Executing Nodes¶
Console Output¶
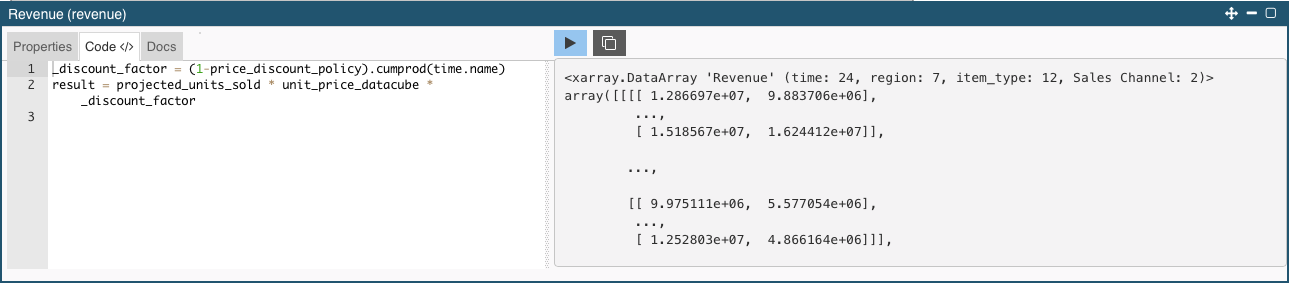
You can run any node after editing its code by pressing CTRL + Enter.
At the right side of the Code window, the console output resulting from running the node will appear.
 Any
Any Pprint() statement written between code lines will display it result here.
Its purpose is to make a quick evaluation of the node, to check if it is properly defined.
Result Explorer¶
Another way to run a node is by pressing CTRL + E. In this way, more complete information about the node properties and its result is displayed.
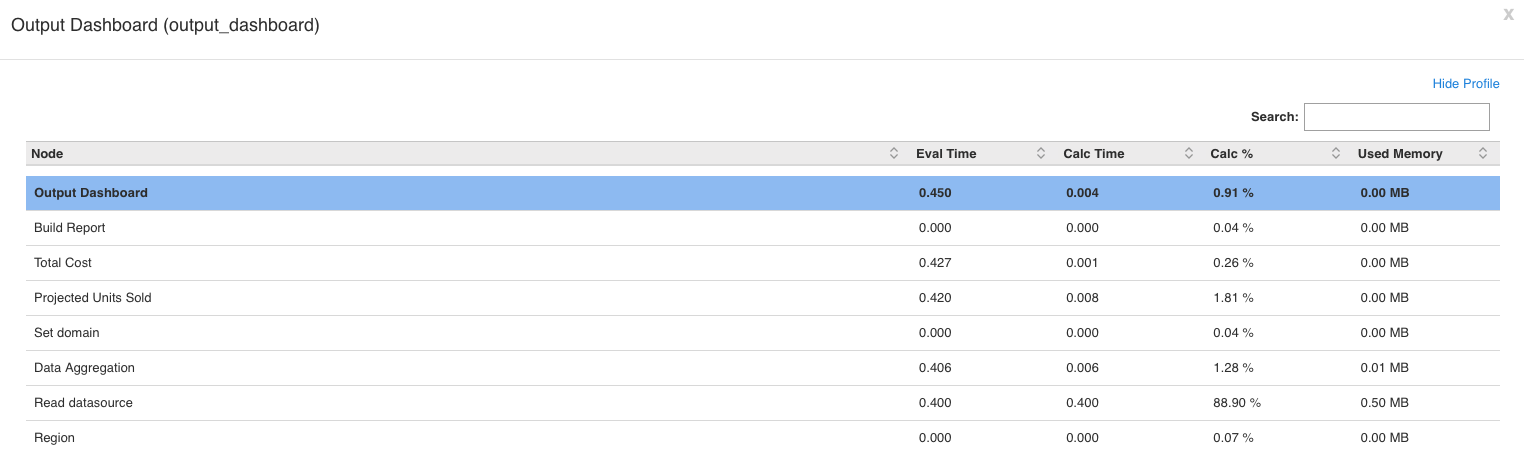
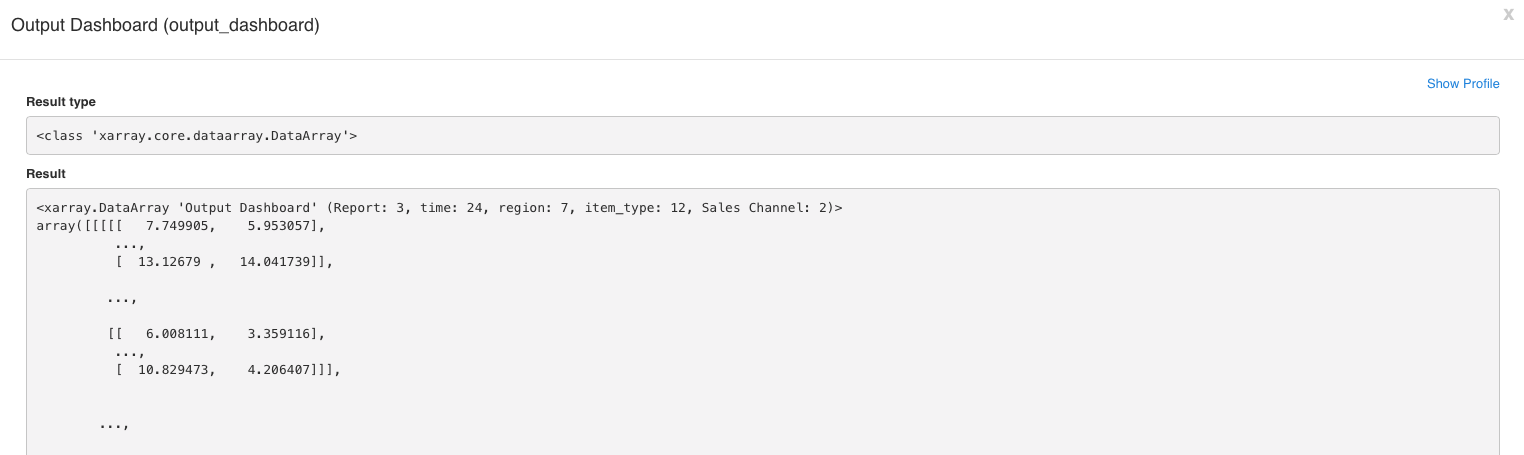 One of the most interesting features accesible through this means of evaluation is the “Show Profile” feature, which displays the calculation path, the calculation time, and the memory usage by step (nodes.)
One of the most interesting features accesible through this means of evaluation is the “Show Profile” feature, which displays the calculation path, the calculation time, and the memory usage by step (nodes.)
Evaluating a Node¶
Press CTRL + R to get its result.
You can evaluate a node by double clicking on it or pressing CTRL + R after selecting it. Unlike the previous running alternatives, the node is run and its result displayed in a new tab, called the “Title” of the node, which has a default table format.
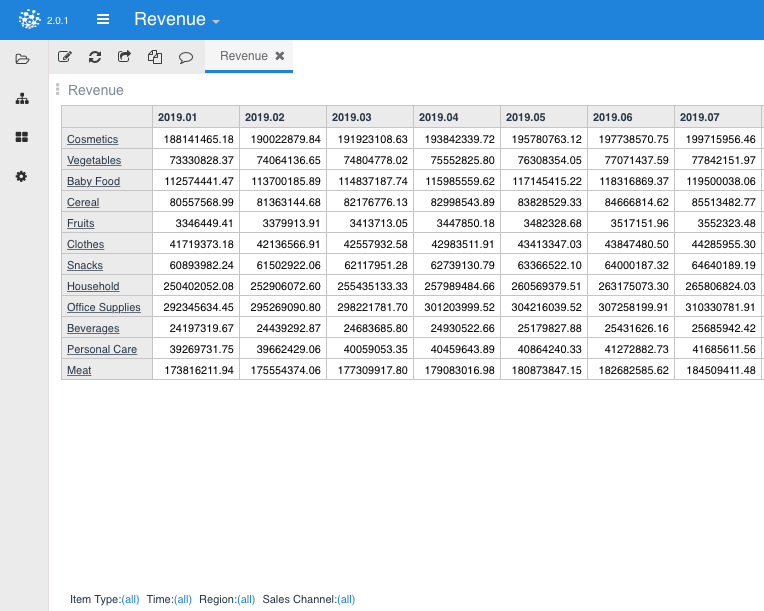
Pyplan natively interprets Numpy matrix, Pandas dataframe indexes, and Xarray dimensions, which will be automatically displayed at the bottom of the table for pivoting and filtering. Default views can be changed using the Edit interface menu that can be launched by clicking on the icon shown in the image below.
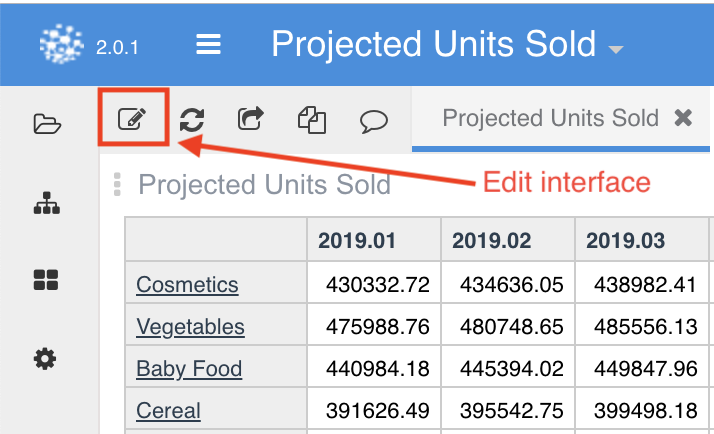
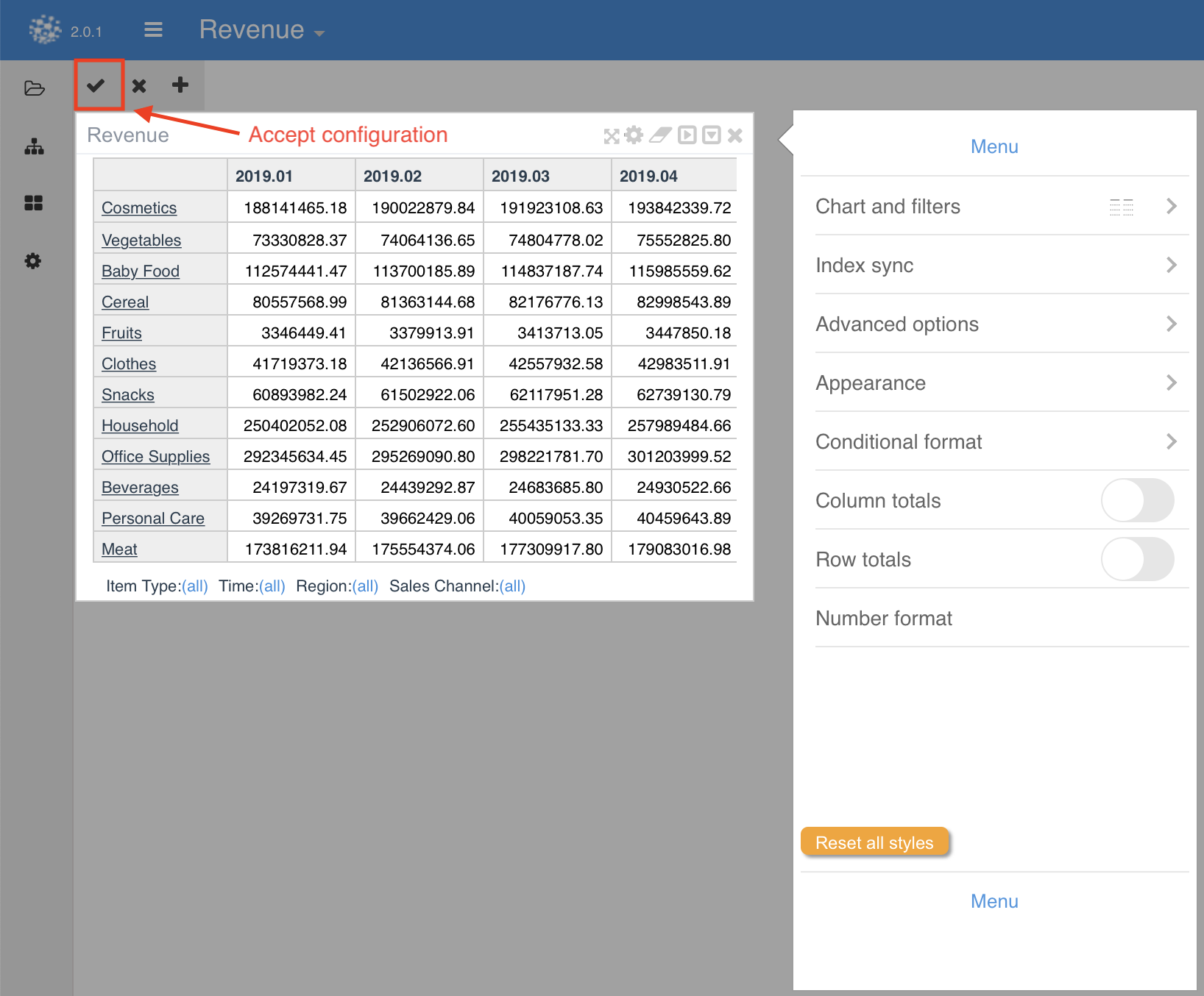
When you click on the Edit interface icon, the configuration menu is launched. Here, you can decide how the node will be rendered. After defining the node visualization configuration, you must accept the changes in order to save them.
Embedded Tools¶
There are some embedded tools that appear when evaluating a node according to the type of result.
For example, any node evaluates as a pandas dataframe object will display the following tools:
 These tools make it easy for non-programmers to start manipulating the basic Python objects without coding.
As you will realize, when operating with these tools, the subjacent Python code is automatically generated, hence inducing analysts to learn how to use Python. This is like saving a macro in Excel.
These tools make it easy for non-programmers to start manipulating the basic Python objects without coding.
As you will realize, when operating with these tools, the subjacent Python code is automatically generated, hence inducing analysts to learn how to use Python. This is like saving a macro in Excel.